System Overview
What is Hydra?
Hydra is a unified real-time streaming platform that enables the ingestion, storage, analysis and distribution of massive amounts of data in near real-time. In other words, Hydra is built for storing large amounts of data very efficiently, and with the capability to query and replicate that data in a streaming-oriented fashion. Hydra consists of several interconnected systems that work together to provide easier data capture, data access and data replication. At the heart of the system is a distributed messaging system based on logging semantics called Kafka. Kafka provides a high performance, highly-available distributed data stream. In the remainder of this document the terms log, stream, data stream and topic may be used interchangeably and represent the fundamental abstraction of the DVS, the movement of data around various systems in near real-time. Layered on top of Kafka is a custom-developed data transformation, transport and routing platform named Hydra. Hydra simplifies and abstracts creating, manipulating and storing data streams.
We are able to do this by leveraging technologies like:
- Akka and the Actor Model for distributed and parallel computation
- Scala, which, along with Akka, gives us the power to leverage asynchronous processing
- Kafka for distributed data storage, although Hydra can be configured to work with any fault-tolerant "sink" or destination
- Apache Avro for validation and serialization of incoming data
- A combination of application-defined metrics collected through Kamon and Prometheus for monitoring system performance and alerting
In a nutshell, Hydra is:
- Distributed
- Asynchronous
- Fault-Tolerant
- Reactive (see: Reactive Manifesto)
But Why?
Why Akka?
We highly recommend reading at least the introduction to akka to understand why it is useful to use for a streaming platform capable of handling huge amounts of data. In short, Akka allows us to build a multi-threaded and distributed application in a safe, developer-friendly way. This helps us avoid many of the common challenges with programming concurrent systems while delivering a high level of quality, efficiency, and speed.
Why Avro?
Avro is our chosen library for validating incoming data to Hydra. The validation level is configurable, although in general Hydra expects that you supply a schema (defined in Avro format: Read Here) to validate your incoming data against. Although this can be tedious, creating and maintaining a schema for your data can help ensure things like:
- Your data contains all the fields and values it needs, this can be particularly important for downstream consumers
- You can seamlessly "evolve" your schema to add/rename/etc fields to have backwards and forwards compatible data structures
- Much, much more!
Why Kafka?
Kafka is at the core of Hydra data storage, although in the future we aim to make Hydra's data storage pluggable and configurable. Kafka provides us MANY great capabilities, here are a few that we use:
- Dumb-Broker/Smart-Consumer model for data processing ensures that we can:
- maintain data for a configurable amount of time without losing it
- support the consumption of that data for many consumers
- Kafka Streams for:
- creating derived internal kafka topics
- simple data replication and streaming to various downstream systems
- An N-partitioned, distributed Log for maintaining data ordering
System Diagrams
Conceptually, Hydra is a collection of libraries and Scala applications that run separately. For the purposes of thinking about the system, we can logically split Hydra into a few different parts:
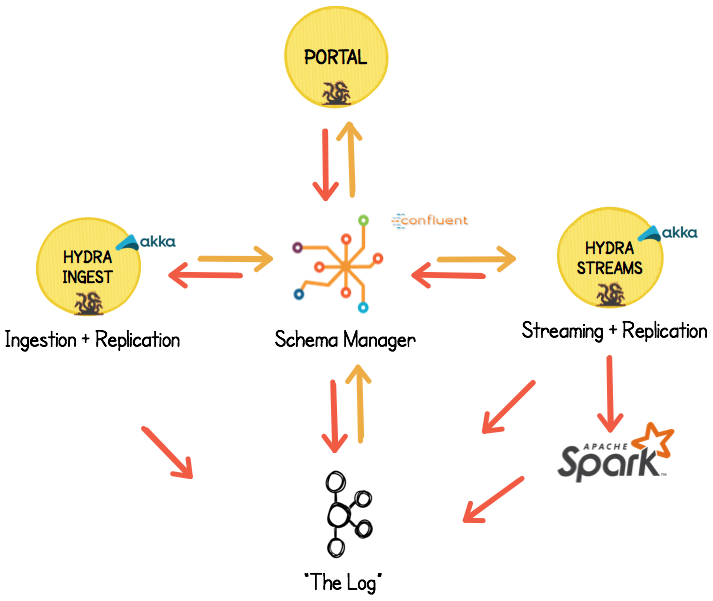
This diagram shows the constituent pieces of Hydra, but the two most important are:
- Hydra-Ingest (Our application for sending data to Hydra)
- Hydra-Streams (Our application for getting data out of Hydra)
At a high level, this is what Hydra-Ingest looks like:
HYDRA_INGEST_DIAGRAM_HERE