Hydra

Hydra is our first evolution with a dynamic real-time streaming data pipeline. The Hydra data platform is designed to function as a central data vascular system (DVS), collecting, aggregating and moving data throughout the organization in real-time, enabling broad real-time analytics and data intelligence. Our mission is a data first culture, where data is driving critical insights, decision making, and powering innovation.
Hydra is a unified streaming platform that simplifies the ingestion, storage, analysis and distribution of large amounts of data in near real-time. It makes data easily accessible and always available for many uses throughout the entire organization, ranging from “big data” batch analysis on top of Spark and Hadoop to real-time streaming pipelines used in event sourcing, systems monitoring and context bootstrapping. While still relatively technical, Hydra is intended to provide a more developer and user-friendly interface to accessing, moving and capturing data.
With Hydra, you can:
- provide a real-time data pipeline at scale in a highly available manner
- browse existing streams to discover new data
- provide shared and curated streams
- provide a data pipeline that is easy to use by the developers and easy to manage
At the core of Hydra
Hydra consists of the following system components:
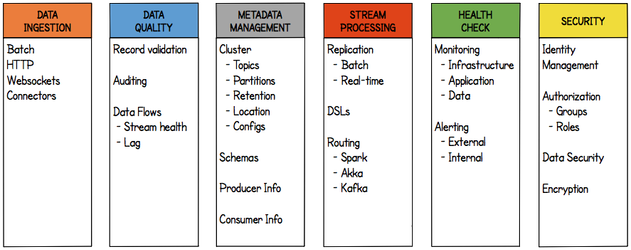
Data Ingestion
See Data Ingestion Overview for system level details
Data Quality
Metadata Management
See Metadata Management Overview for system level details.
Stream Processing
See Stream Processing Overview for system level details
Health Check System
Product – What (system, application, data quality metrics monitoring/alerting)
See Health Check System Overview for system level details.
Security System
Access / Authentication / Authentication / Data Security
|